To Predict Where M365 Copilot Struggles, You Need to Understand How It Searches
What you'll learn
- Why Copilot's failures are predictable, not random
- The specific content types and formats Copilot can't search properly
- Practical steps to improve what Copilot can find — and where SharePoint search fills the gap
People often run into situations where Microsoft 365 Copilot produces an answer that’s flat-out wrong—or no answer at all—to a question that feels simple. The common reaction? A shrug and “Well, it’s AI, what do you expect?”
Consultants sometimes point to flaws in your information architecture, but that’s usually not the real reason. While information structure and metadata do matter, they have only a small influence on what Copilot can and can’t do. The truth is more basic: if you want to predict where Copilot will stumble, you have to understand how it actually searches for information before it generates an answer.
Most people assume Copilot reads through all your documents, SharePoint sites, Teams chat and email in the same way a person might, only faster. It doesn’t. For a deeper dive into the mechanics, check out Copilot’s Other Large Language Model. But in short: Copilot doesn’t analyze your content directly. It relies heavily on search, and on extensive winnowing of search results, and that shapes its strengths—and its blind spots.
PointFire Search Optimizer addresses several of these blind spots directly — adding query rewriting and per-result relevance summaries to SharePoint search. See how it works →
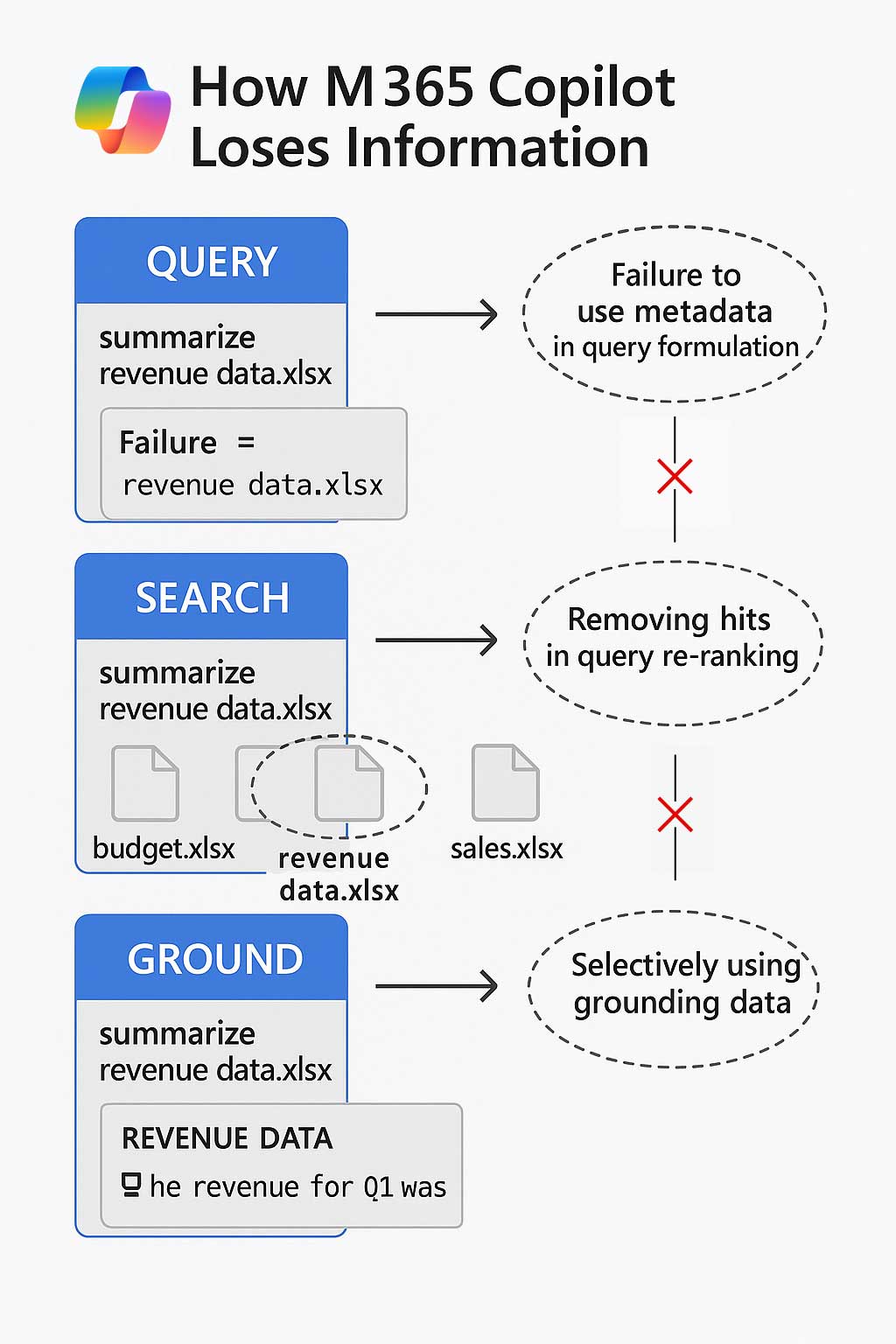
A lot has been said about Copilot’s semantic index. Its semantic index is indeed remarkable, but it is far from unique; semantic indexes have been with us for decades. The semantic index is good at finding documents that have the same topic as the query but not the same words. That means it can find certain things that keyword search would not find. That’s all well and good, but the semantic index is quite bad at finding things that keyword search would have easily found. It finds a few things that are relevant and that keyword search would have missed, but it misses a lot that is even more relevant and that keyword search would have missed, but it includes a lot of things that are completely irrelevant.
This is why Copilot uses a hybrid search approach, with semantic search and keyword search. Does it send all of that information to the LLM? No, this is far too much information for the LLM. Copilot has to be very selective in what it sends to the LLM, a few dozen sentences is all it can take (it varies, but this is an order of magnitude). Certainly not entire documents.
Having searched in two indexes and gotten two different lists of things (keyword search identifies documents, while semantic search typically indexes passages within documents individually), it then has to combine the lists and re-rank the combined list.
The unfortunate thing about re-ranking is that one of the strengths of Microsoft Search via Graph is its ranking, using social information like who interacts with the document and what is their relationship with you and which documents are popular recently, and a lot of that ranking is lost when Copilot does its re-ranking. Semantic search, contrary to popular belief, doesn’t have that social information. However, the ranking information is not completely lost because, drum roll, Copilot throws away all but the top 50 or so results, when ranked according to the original rankings, before it does its own re-ranking within those 50. Then Copilot re-ranks and uses that re-ranking to throw away most of what’s left, leaving only a few dozen top-ranked sentences. Some sentences that survive the cull are from the same document, and some are from unrelated documents, chats, or emails. Some contradict each other or were written based on a different methodology. The good thing is that some of the relational and social interaction goodness in the keyword search that was thrown away from the keyword search results, and that was never there in the first place in the semantic search gets put back in as criteria to assist in the final re-ranking.
Even for the few dozen sentences that survive this process, what is called the LLM’s “grounding data”, the LLM is going to pick and choose what part of that it thinks is relevant to your original question, and what subset of that is what makes for a simple and compelling answer. This is where the LLM’s weaknesses come in, about math, about the structure of words, about reasoning, about data structure, etc., and where it might use its prior knowledge from the internet instead of your organization’s documents if it finds its prior knowledge more relevant.
You also have to remember that in the ranking process, the information from your organization has been stripped of its context. So for instance, a document might contain a list of factors that you must not use when evaluating a loan application or a job candidate, but the sentence that gets selected in the re-ranking has some of those factors but not the introductory sentence saying not to use them. The LLM is also keen to make links between different parts of the grounding data even if they are unrelated, and if there are conflicting statements it has no way to determine which is more reliable. Having too much grounding data is a good way for the LLM to ignore or misunderstand some of it. So is complexity, subtlety, or ambiguous phrasing.
Granting Copilot the permission to search the internet is a good way to introduce information that conflicts with your internal data, but even if you don’t allow it, ChatGPT was trained on the internet. That knowledge is hardcoded in the model and Microsoft won’t let Copilot retrain on your data. If there is a common misunderstanding about your field out in the internet, Copilot will use it.
So your task is to figure out what information each of the two search subsystems is going find when queried, which information is likely to be ranked among the first few passages, and how the LLM will fashion that into something that looks like an answer to the question.
The predictable gaps
Unsupported formats
If your information lives in formats that Microsoft Search or the Semantic Search can’t index, Copilot won’t see it. This includes certain PDFs, scanned documents without OCR, long documents, or specialized file types. If Search can’t read it, Copilot can’t use it.
For email, it can search user mailboxes, but not Delegated mailboxes or shared mailboxes, or archived mailboxes.
In the case of encrypted or unsupported file formats, Microsoft Search can find it, but not retrieve it, based on title and metadata alone, but the Semantic index won’t even record its existence.
Classic SharePoint pages and modern web parts
Classic SharePoint pages often don’t play nicely with Copilot. Much of the content embedded in old-style pages and web parts isn’t indexed in a way Copilot can use. If your organization still relies on classic sites, expect inconsistent results.
Even for modern pages, part of the page won’t be indexed. The content of many webparts is hidden in metadata or elsewhere, and the semantic index won’t touch it.
Large amounts of information
When you ask Copilot a question that involves a large amount of data, whether it’s found in a single document or spread over multiple documents, it won’t do it. If the required information isn’t concentrated in a few sentences, then most of that content will be cut before it reaches the LLM.
Data buried in later pages
Similarly, if the key information is several pages deep in a Word document or PDF, Copilot may never reach it. Search indexes typically capture only the beginning or selected passages. It may not get indexed, or it may not get sufficient priority during the re-ranking to make the final cut. Important details hiding on page 37 may as well not exist.
Metadata blind spots
Metadata is gold for filtering and organizing in SharePoint and search. But Copilot doesn’t always make full use of it. The semantic index does not contain the document metadata at all, the indexing is essentially only the text of the document. That means that even if your query is phrased in a way that you want the information to come from a certain type of document that is defined by the metadata, the semantic query will ignore it altogether unless that information is also in the text, and even the keyword query, which does have metadata in its index, is not very likely be able to formulate a search query that uses that metadata effectively. It will certainly be unable to use your custom metadata. If you create a choice column or a managed metadata column called “Status” and with possible values of “Active”, “Under Review”, “On Hold”, etc., the query processing will be unable to map the meanings of your query to the name of the column or its values. This is part of the consequences of not training the AI on your data. Only a few built-in metadata columns such as Author get used.
A lot of well-meaning experts will tell you that in order for Copilot to give you good results, you must clean up your data architecture and use more metadata. That’s a good idea in general, but it doesn’t do very much for Copilot.
If your content strategy relies heavily on tags, properties, or custom metadata to carry meaning, Copilot may overlook it.
Lists
SharePoint lists can be incredibly useful, but Copilot doesn’t handle them as cleanly as documents. Structured data in list items often gets flattened or ignored, which limits Copilot’s ability to pull meaningful answers. Lists are mostly metadata so most parts of Copilot pay little or no attention to them.
Multiple languages
If your tenant spans multiple languages, Copilot will only really provide answers where the language of the document matches the language of the query. If your current preferred language is different, then Copilot may give you an answer in your language, but it won’t translate your query to the language of the documents. The keyword index can’t find a match on the words in the query. The semantic index theoretically could, but currently it chooses not to rather than risking having incomplete and inaccurate results.
Multilingual content isn’t consistently handled, and Copilot may produce incomplete or biased answers as a result.
Tables of content
Tables of content within documents are a particular issue. When you search, you might find a lot of your keywords close together in a table of contents, but that doesn't mean that all those terms are related. Most likely they are not related, that’s why the author put them in separate sections. Tables of contents or glossaries in documents will fool a lot of algorithms and the LLM will try to construct a little story around the fact that all these terms are apparently appearing together in one long sentence. Beware of those tables.
Semantic Drift in Query Expansion
English, in particular, uses the same word for multiple meanings. The AI in Copilot doesn’t deal with meanings, only words and their neighbouring words. It can show you things that are associated with a different sense of one of the words, and the semantic index might double down on this error. A “release” is different whether the context is automotive or legal. If your query is about a “tort”, Copilot might want to talk about pastry. The fact that Microsoft won’t let it train on your data is part of the problem.
What you can do
Microsoft 365 Copilot Search
To get insight into how Copilot searches and what it prioritizes, try Microsoft 365 Copilot Search. It’s not quite the same as what Copilot uses internally, but it gives you a good idea of the types of items that are found and prioritized. If you’re more code oriented, the Microsoft 365 Copilot Retrieval API (preview) is even more similar to what Copilot uses internally, and you can run experiments with different queries and document formats.
Use curated acronyms in Copilot Search
This is a new feature. It seems very similar to the acronym feature that is already in SharePoint Search and the one that is in Microsoft Search, but also includes short answers to common questions. Does it affect the search that Copilot chat uses internally? Not sure.
Use groups and maintain the org chart
These are the pieces of metadata that Copilot uses in prioritizing items: Your relationship to the author of the document. Groups are great. They carry permissions, but also define who you interact with, for instance in Teams. Always use M365 groups, not SharePoint permission groups or individual permissions. You can maintain the org chart for example in Outlook. Copilot uses this metadata to prioritize documents by people you work with.
Cracking and other skillsets
I am adding this in case it becomes a future feature. Skillsets is a term that is used in Azure AI Search to refer to pre-processing or enrichment, like summarization or OCR, that you can do to the version of the document that is being indexed. Copilot’s internal search is based on Azure AI Search, but this functionality is not surfaced in Copilot. You could use this to add information in textual form that it ignores, like metadata, or to hide information within a document that confuses it, like the table of contents.
In the absence of this functionality, you can use Syntex or Agents to do this to the document itself.
Add abstracts and document summaries, preferably within the document text.
Add a cover sheet or information sheet to documents, with a summary of the important parts of the document, and some of the metadata in text form. This will help the semantic indexer, which doesn’t do well with metadata, to find the document. Remember that just because Copilot finds the document doesn't mean it will find the relevant parts of the document, since its unit of indexing is passages (a sentence or two) not documents. This is why you need a summary close to this surfaced metadata.
Prompt engineering
Clearly define what you are looking for, how to find the information to base it on, and what an appropriate answer looks like. This helps a lot with the ChatGPT engine that is formulating the answer, but it also helps with the query processing that is trying to convert your question into a set of search queries. Your documents are all written in the form of answers, not questions, so telling it what an answer looks like gives it extra hints in formulating search queries.
Choice of words
Also remember your query is used by several parts of Copilot. It is used by the LLM in formulating the answer, but it is also used by the keyword search to find exact matches of keywords and phrases, matching the words in your query to the words in your document, and it is used by the semantic search to generate a vector corresponding to similar words and concepts, and used to re-rank results. It corrects some typos, but it’s more accurate if you correct your own. Use words and phrases similar to what is found in the documents, avoid words with multiple senses, and try to make your query unambiguous and grammatically correct.
Permissions
Don’t be afraid to hide information from users if it is not relevant to their work. Copilot’s semantic index is not good at scoping the source of information to one site or one source of information. If the user has access to a document, even in a place they have never visited and didn’t know they could see, then it will be returned in their search results, and might drown out more relevant information that is more relevant to their work.
Avoid oversharing
The SharePoint Advanced Management add-on is a great way to review who has access to what but probably shouldn’t. You can use it to reduce oversharing and content sprawl. If you also have a Copilot license, it can generate even more AI-powered insights and optimize access specifically for best Copilot results.
Configure Restricted Content Discovery
Short of actually denying access to SharePoint sites and libraries, you can configure the Restricted Content Discovery feature on a site to ensure that by default the information on that site is not discoverable by Copilot in tenant-wide searches, but is still available in site-level searches. Do not overuse this feature as it can have a negative impact on Copilot use cases with a legitimate need to access those files. To restrict it more completely, you can edit the site’s crawl setting on the SharePoint Search Administration page
Don’t use tabular data for layout or for text
Copilot is not good at visual information like table layout. It can be used for numbers if the table layout is very simple, otherwise all the text will be mased together and read as one very long sentence.
The bottom line
Copilot’s failures aren’t random. They’re usually tied to predictable limitations in what it can search and how it indexes that information. Understanding these limits helps you set realistic expectations—and avoid blaming “bad AI” or “bad information architecture” when the real issue is simply that Copilot can’t see what you’re asking about.
If you want Copilot to work well, make sure your content lives in supported formats, is easy to reach early in documents, and doesn’t rely too much on metadata, lists, or classic SharePoint pages. And if you’re multilingual, don’t expect perfection yet.
It’s unfortunate that Microsoft doesn’t provide any insight into how your question was processed. For example what queries did it send to the search systems, and which documents and passages did it prioritize. It’s also unfortunate that tuning its LLMs on your data is not an option.
The key to better results isn’t wishing for smarter AI—it’s making sure Copilot can actually find the information it needs in the first place.
That's exactly what PointFire Search Optimizer helps with. Book a demo and we'll show you how.
Dig deeper into how SharePoint and Copilot actually work
- Why Copilot Doesn't Replace SharePoint Search (And Isn't Supposed To) - The two systems use completely different retrieval pipelines — understanding the difference changes how you deploy both. Read more
- Copilot vs PointFire Search Optimizer: Which Handles SharePoint Search Better?A side-by-side look at how each tool retrieves, ranks, and surfaces content from your Microsoft 365 tenant. Read more
- Copilot's Weak Spots Are Predictable . If You Know How It SearchesThe same retrieval pipeline that powers Copilot also explains exactly where and why it fails. Read more
Related Topics