Copilot ’s Other Large Language Model: How Copilot Uses Multiple LLMs for Semantic Indexing and Search
Microsoft hasn’t disclosed all the details of how Microsoft 365 Copilot works, but there are enough hints to conclude that there is more than one Large Language Model (LLM) at work.
LLM1 – The ChatGPT Variant
The first and most familiar Copilot LLM is essentially ChatGPT. We will call it LLM1. Calling it ChatGPT is an over simplification because the Copilot orchestration layer (which itself uses a small language model!) can choose a similar but different model, but for simplicity let’s say it’s just ChatGPT. It’s what generates the chatty text when Copilot answers a question. But while OpenAI’s ChatGPT answers questions mostly using information embedded into the model when it was trained months or years before, Copilot uses it for Retrieval Augmented Generation (RAG). This means it queries your data and possibly the internet to find context that it can feed to ChatGPT, LLM1. That allows Copilot to provide an answer based more on relevant documents stored in your tenant than on last year’s internet.
Why Copilot Doesn’t Train on Your Data
What is clear is that the LLMs that Copilot uses are NOT trained or tuned on your documents. Training it on your data would give better answers but it would be harder to guarantee that no information is leaked to people who don’t have permission to see it. It’s a compromise: the answers are not quite as good as they could be, but they are guaranteed to respect your permissions.
LLM 2 - Semantic Indexing
The second LLM (LLM2) that I’m talking about is less visible. It is the LLM that is used for semantic indexing. Its existence is an educated guess based on multiple hints. Microsoft describes Copilot’s semantic index in several documents, but these are very general descriptions
https://learn.microsoft.com/en-us/microsoftsearch/semantic-index-for-copilot
https://www.youtube.com/watch?v=KtsVRCsdvoU
Copilot has a tenant-level semantic index for anything that is accessible to more than one user or that is public, and there is also a user-level semantic index for anything related to a single user.
What Is a Semantic Index?
You are probably familiar with a lexical index, also known as a full-text index. It is what SharePoint’s search uses. It is essentially like the index at the back of a book: for every word or phrase there is a set of page numbers telling you where in the document the word is found. It’s more sophisticated than that, the M365 lexical index is not at the page level and refers to many documents and other sources of text and the index has detailed information about where exactly the word is found, and it knows a lot about the document properties as well, but you can think of it as a list of words and their location.
“Lexical” means pertaining to words, as in lexicography, while “semantic” is related to meanings. A semantic index isn’t for words, it’s for concepts and relationships between them. There are many different possible types of semantic indexes. We know that Copilot’s semantic index is made of vectors. Vectors are mathematical structures where similarity between vectors means that the texts they represent are semantically similar, that is to say they mean similar things.
How Copilot Uses Vectors and Embeddings
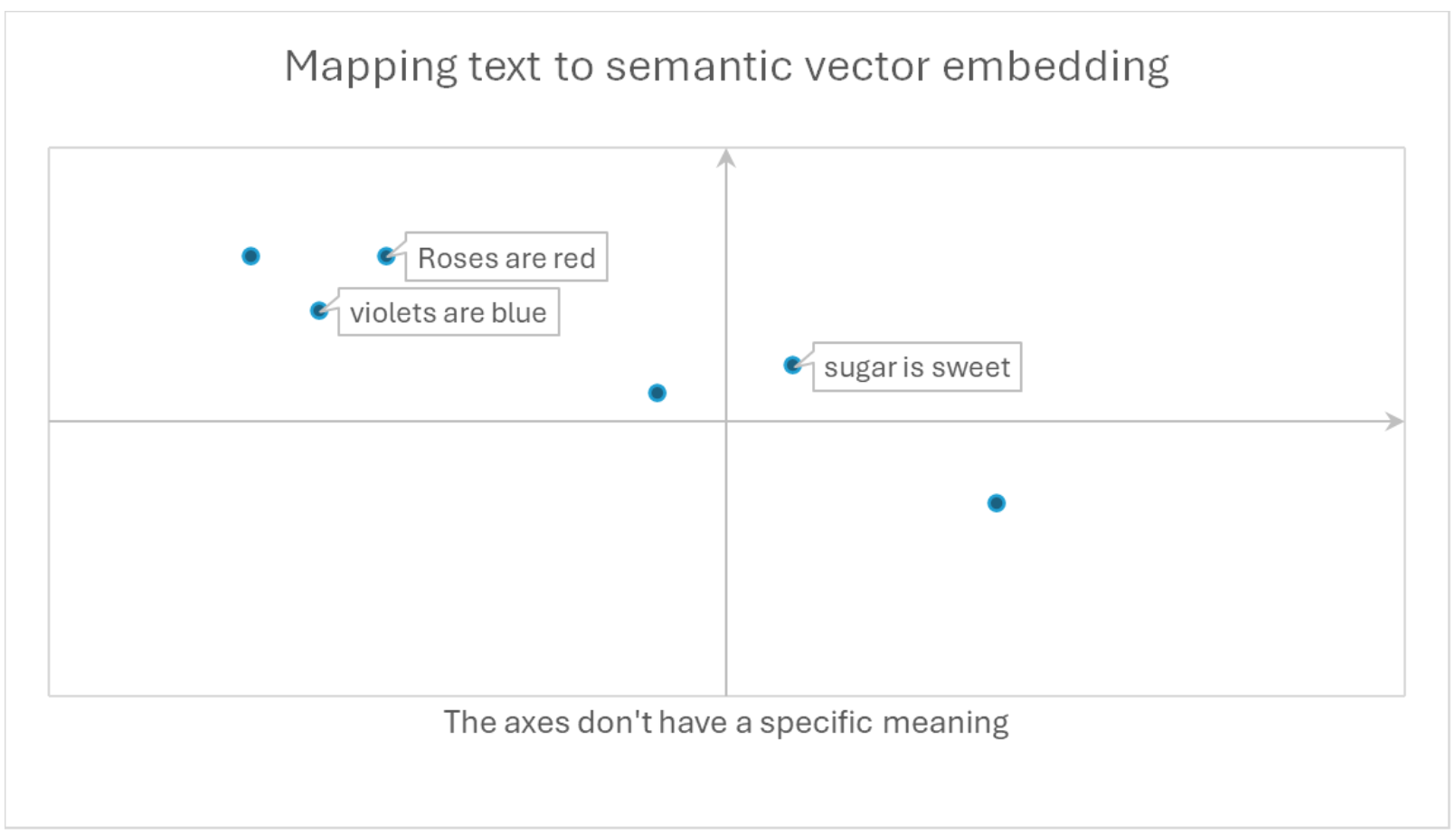
For example, “Roses are red” is very close to “violets are blue” because it has learned that the words “rose” and “violet” can be substituted for each other in a similar context, and the same with “red” and “blue”. It knows nothing about the meaning of those words, just the company they keep with other words such as “grow”, “fragrance”, and “bouquet”.
There are many such vector representations or “embeddings” that are possible. The simplest (!) ones are vectors of about 50,000 numbers, each one referring to one of the 50,000 or so base words in the English language. These can be enhanced with semantic repositories, such as an ontology, wordnet or thesaurus to look up when different words or phrases have a related meaning. These are called sparse vectors because most of the numbers are zero. More recent embeddings use unsupervised learning: the algorithm that trains on a large corpus of text discovers similarities between words by analyzing the text documents and noticing that some words occur together, or they use knowledge graphs, seeing relationships between documents and other types of data. Classic statistical algorithms like Latent Semantic Indexing were commonly used for this until about 10 or 15 years ago.
More modern methods use a specialized neural language model with much more dense vectors, only hundreds of numbers, which learn semantic similarities by themselves, using algorithms like word2vec, a small neural network. These numbers aren’t directly meaningful, but word2vec learns what words are likely to appear close to each other in sentences, and because of this it generates similar vector for terms that are likely to be interchangeable in a sentence or to appear in the same sentence and therefore have similar meanings.
In recent years, even better models have emerged, based on the Transformer architecture (Transformer is the “T” in “GPT”) such as ELMo (Embeddings from Language Model) and BERT (Bidirectional encoder representations from transformers). Unlike the unidirectional decoder-only GPT, these transformer models are bidirectional encoder-decoder models that can see more word relationships. They are a lot better than word2vec at determining when words in a sentence are related even if they are not close together.
The “Sentence transformer” algorithm is one of that new generation of vector encoders. It’s open source, and it’s very popular and effective. An even better set of models, which keep improving and getting faster are the OpenAI prebuilt text embeddings. Their explanation of how text embeddings work is particularly clear https://openai.com/index/introducing-text-and-code-embeddings/ These OpenAI models are descendants of ChatGPT.
It is my guess that one of these is the one that is used by Azure AI Search and probably also by Copilot. It doesn’t need to be retrained on your data (again, it would be better if it were) and Microsoft is adamant that it doesn’t train or fine-tune on your data. Copilot might also use a sentence transformer, those can also be used pretrained.
So this is the lesser-known second LLM that Copilot uses, the one that generates the vectors that make up the semantic index. We will label it LLM2. But wait, there’s more! A third LLM?
LLM3 – Re-Ranking the Results
There’s more to using a semantic index than just generating it and querying it, although that topic alone is interesting. Mathematically it’s simple: for every document or sentence or passage, generate a vector and store it in a vector database, all in advance. When someone queries, encode the query (suitably modified for this purpose) in the same way as a vector and find the nearest vectors corresponding to the documents that were indexed. You can use different vector comparison algorithms, whether cosine or dot product or Faiss (Facebook AI Similarity Search), whatever your vector database performs well with. However vector search is computationally expensive so a lot of algorithms don’t find all the closest matches, in a tradeoff between accuracy and performance, but they will find most of them.
The Limits of Semantic Search Alone
This procedure will find a lot of passages that are semantically similar to the query, some that are appropriate and many that are not. Ironically it doesn’t do well with exact matches. So for instance the semantic index might think that “violets are blue” is a fine answer to “What colour are roses?” and miss “roses are red”.
How Hybrid Search Improves Results
The solution is a hybrid search approach. When the query comes, Copilot searches simultaneously in the lexical (full-text) index and the semantic (vector) index. This gives two lists of documents, each one ranked according to different criteria. Because the lexical search is using Microsoft Search via Graph, the ranking is based mostly on the words in the document, but also includes metadata and “social” information like whether the document author is someone that has a direct or indirect work relationship with me or how recent or popular is the document.
Reranking
It’s more difficult for semantic search to use some that information, but it can be used in the “reranking” of the two lists. It is called “reranking” because it is time and resource intensive, so first it lets faster ranking algorithms score all the results, then re-ranks only the top 50 results or so.
Azure AI Search has a vector semantic index using deep learning similar to the one used in Bing, that it uses to re-rank search results. It was developed in cooperation with Bing and Microsoft research. Microsoft uses a lot of the same terms to describe the semantic index in Azure AI Search and the one in Copilot, and some of the Microsoft engineers who talk about Copilot’s semantic indexing actually work for Azure AI Search. Odds are, both products use the same or similar semantic indexing and re-ranking technology.
Azure AI Search offers reranking for hybrid search. The idea is to evaluate the combined results of lexical search and semantic search using common criteria to narrow down the list of documents. The best way to do this, according to technical papers and blogs from Microsoft? Yet another LLM. Let’s label it LLM3. This re-ranking algorithm that is used by Azure AI Search and is probably similar to the one used by Copilot. It’s a bit confusing since Azure AI Search offers several ranking algorithms for hybrid search, many of which don’t use LLMs. Azure AI Search can also use specified metadata fields and relationships to help with ranking.
So it seems from several hints that Copilot is probably using a large language model to re-rank, and that it includes metadata fields and relationships. This is called Semantic Ranking, and the specific model, also adapted from Bing, uses neural network language model but not generative AI. That would make it the third LLM.
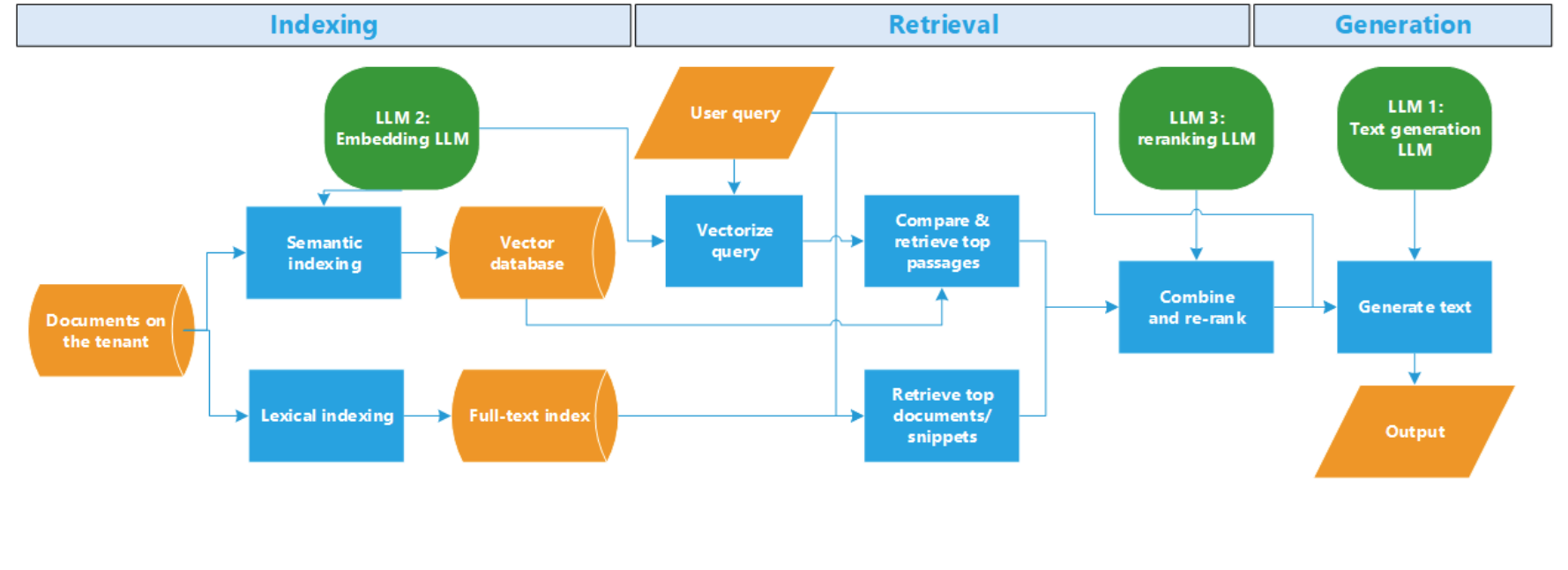
Only after this searching and ranking has been done does Copilot report what it thinks is the most closely related information in the tenant and send it to the generative text LLM. It doesn’t send all the matching text it found, it’s a curated subset of chunks from multiple documents. The ChatGPT variant, which we call LLM1, will distill it further, perhaps extrapolating a bit, and phrase the output in the form of an answer to the original question.
Putting it all together
Conclusion: Why Understanding Copilot’s LLMs Matters
In summary,
- A specialized LLM (LLM2) creates a semantic index of all your supported data in advance, based mostly on their text, in the form of vectors
- The same LLM is used on your query, also a vector
- Comparing vectors identifies semantically similar documents with different words
- A full-text index is used to identify lexically similar documents using the same words
- The two results are combined and ranked using fast algorithms, then re-ranked using a second specialized LLM (LLM3)
- After checking that the user has access to the documents it found, text is extracted from the top documents, and the top text from the combined list of top documents is selected
- Selected text and the (suitably modified) original query are sent to the generative LLM (LLM1), a variant of ChatGPT, asking it to synthesize and summarize the information from multiple documents into a single answer.
Related Topics